Let X1,X2,…,Xn be i.i.d., each with mean μ and SDσ. You can think of X1,X2,…,Xn as draws at random with replacement from a population, or the results of independent replications of the same experiment.
Let Sn be the sample sum, as above. Then
E(Sn)=nμVar(Sn)=nσ2SD(Sn)=nσ
This implies that as the sample size n increases, the distribution of the sum Sn shifts to the right and is more spread out. The expectation goes up linearly in n, but the SD goes up more slowly.
Answer
(a) 250
(b) 19
Here is an important application of the formula for the variance of an i.i.d. sample sum.
Let X have the binomial (n,p) distribution. We know that
X=j=1∑nIj
where I1,I2,…,In are i.i.d. indicators, each taking the value 1 with probability p. Each of these indicators has expectation p and variance pq=p(1−p). Therefore
E(X)=npVar(X)=npqSD(X)=npq
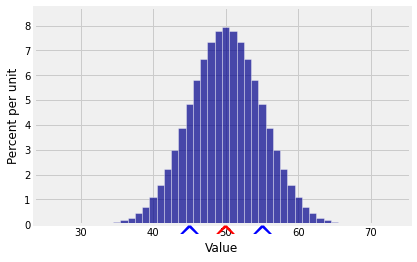
For example, if X is the number of heads in 100 tosses of a coin, then
E(X)=100×0.5=50SD(X)=100×0.5×0.5=5
Here is the distribution of X. You can see that there is almost no probability outside the range E(X)±3SD(X).
We showed earlier that if X has the Poisson (μ) distribution then E(X)=μ, Var(X)=μ, and SD(X)=μ. Now we have a way to understand the formula for the SD.
One way in which a Poisson (μ) distribution can arise is as an approximation to a binomial (n,p) distribution where n is large, p is small, and np=μ. The expectation of the binomial becomes the parameter of the approximating Poisson distribution, which is also the expectation of the Poisson.
Now let’s compare the standard deviations. The standard deviation of the binomial is
npq≈np because the small p implies q≈1
But np=μ in this setting, so the SD of the binomial is approximately μ. That’s the SD of its approximating Poisson (μ) distribution.