🎥 Definition of Expectation
Let have density . Let be a real valued function on the real line, and suppose you want to find . Then you can follow a procedure analogous to the non-linear function rule we developed for finding expectations of functions of discrete random variables.
Write a generic value of : that’s .
Apply the function to get .
Weight by the chance that is just around , resulting in the product .
“Sum” over all , that is, integrate.
The expectation is
Technical Note: We must be careful here as is an arbitrary function and the integral above need not exist. If is non-negative, then the integral is either finite or diverges to , but it doesn’t oscillate. So if is non-negative, define
For a general , first check whether is finite, that is, whether
If it is finite then there is a theorem that says exists, so it makes sense to define
Non-technical Note: In almost all of our examples, we will not be faced with questions about the existence of integrals. For example, if the set of possible values of is bounded, then its expectation exists. But we will see a few examples of random variables that don’t have expectations. Such random variables have “heavy tails” and are important in many applications.
All the properties of means, variances, and covariances that we proved for discrete variables are still true. The proofs need to be rewritten for random variables with densities, but we won’t take the time to do that. Just use the properties as you did before. The Central Limit Theorem holds as well.
Answer
15.3.1Uniform ¶
The random variable is uniform on the unit interval if its density is flat over that interval and zero everywhere else:
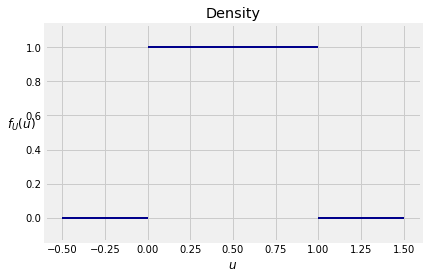
The area under over an interval is a rectangle. So it follows easily that the probability of an interval is its length relative to the total length of the unit interval, which is 1. For example, for every pair and with ,
Equivalently, the cdf of is
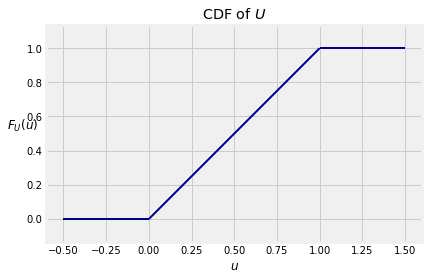
The expectation doesn’t require an integral either. It’s the balance point of the density “curve”, which is 1/2. But if you insist, you can integrate:
For the variance, you do have to integrate. By the formula for expectation given at the start of this section,
15.3.2Uniform ¶
Fix . The uniform distribution on is flat over the interval and 0 elsewhere. Since its graph is a rectangle and the total area must be 1, the height of the rectangle is .
So if has the uniform distribution, then the density of is
and 0 elsewhere. Probabilities are still relative lengths, so the cdf of is
The expectation and variance of can be derived with little calculation once you notice that can be created by starting with a uniform random variabe .
Step 1: is uniform on
Step 2: is uniform on
Step 3: is uniform on .
Now is a linear transformation of , so
which is the midpoint of . Also,
Answer
(a) ,
(b) ,
15.3.3Example: Random Discs¶
A screen saver chooses a random radius uniformly in the interval centimeters and draws a disc with that radius. Then it chooses another radius in the same way, independently of the first, and draws another disc. And so on.
Question 1. Let be the area of the first disc. Find .
Answer. Let be the radius of the first disc. Then . So
np.pi * (4/12 + 1)4.1887902047863905Question 2. Let be the average radius of the first 100 discs. Find a number so that .
Answer. Let be the first 100 radii. These are i.i.d. random variables, each with mean 1 and variance . So and
sd_rbar = ((4/12)**0.5)/(100**0.5)
sd_rbar0.057735026918962574By the Central Limit Theorem, the distribution of is approximately normal. Let’s draw it using Plot_norm.
Plot_norm((0.8, 1.2), 1, sd_rbar)
plt.xlabel('Radius in Centimeters')
plt.title('Approximate Distribution of Sample Mean Radius');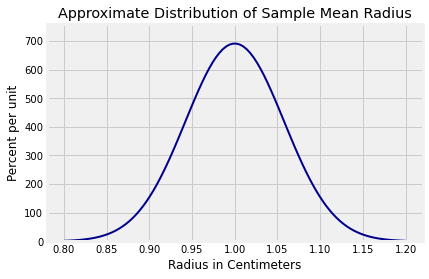
We are looking for such that there is about 99% chance that is in the interval . Therefore is the 99.5th (not 99th) percent point of the curve above, from which you can find .
z = stats.norm.ppf(0.995)
z2.5758293035489004c = z*sd_rbar
c0.14871557417904838We can now get the endpoints of the interval. The graph below shows the corresponding area of 99%.
1-c, 1+c(0.8512844258209517, 1.1487155741790485)Plot_norm((0.8, 1.2), 1, sd_rbar, left_end = 1-c, right_end = 1+c)
plt.xticks([1-c, 1, 1+c])
plt.xlabel('Radius in Centimeters')
plt.title('Gold Area is Approximately 99%');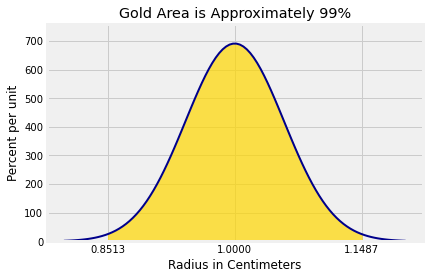
Answer
Roughly normal, mean , variance