Let be a random variable with a beta density. Given , toss a -coin times and observe the number of heads. Based on the number of heads, we are going to:
Identify the posterior distribution of
Predict the chance of heads on the st toss
21.1.1Beta Prior¶
For positive integers and , we derived the beta density
by studying order statistics of i.i.d. uniform random variables. The beta family can be extended to include parameters and that are positive but not integers. This is possible because of two facts that you have observed in exercises:
The Gamma function is a continuous extension of the factorial function.
If is a positive integer then .
For fixed positive numbers and , not necessarily integers, the beta density is defined by
We will not prove that this function integrates to 1, but it is true and should be believable because we have seen it to be true for integer values of the parameters.
To simplify notation, we will denote the constant in the beta density by .
so that the beta density is given by for .
Beta distributions are often used to model random proportions. In the previous chapter you saw the beta distribution, better known as the uniform, used in this way to model a randomly picked coin.
You also saw that given that we know the value of for the coin we are tossing, the tosses are independent, but when we don’t know then the tosses are no longer independent. For example, knowledge of how the first toss came out tells us something about , which in turn affects the probabilities of how the second toss might come out.
We will now extend these results by starting with a general beta prior for the chance that the coin lands heads.
21.1.2The Experiment¶
Let have the beta distribution. This is the prior distribution of . Denote the prior density by . Then
Given , let be i.i.d. Bernoulli . That is, given , toss a -coin repeatedly and record the results as .
Let be the number of heads in the first tosses. Then the conditional distribution of given is binomial . It gives you the likelihood of the observed number of heads given a value of .
🎥 Conjugate Priors
21.1.3Updating: The Posterior Distribution of Given ¶
Before running the experiment, our prior opinion is that has the beta distribution. To update that opinion after we have tossed times and seen the number of heads, we have to find the posterior distribution of given .
As we have seen, the posterior density is proportional to the prior times the likelihood. For ,
because and do not involve .
You can see at once that this is the beta density:
This beta posterior density is easy to remember. Start with the prior; update the first parameter by adding the observed number of heads; update the second parameter by adding the observed number of tails.
21.1.4Conjugate Prior¶
The prior distribution of the probability of heads is from the beta family. The posterior distribution of the probability of heads, given the number of heads, is another beta density. The beta prior and binomial likelihood combine to result in a beta posterior. The beta family is therefore called a family of conjugate priors for the binomial distribution: the posterior is another member of the same family as the prior.
21.1.5MAP Estimate: Posterior Mode¶
The MAP estimate of the chance of heads is the mode of the posterior distribution. If and are both greater than 1 then the mode of the posterior distribution of is
🎥 Prediction
21.1.6Posterior Mean¶
The posterior mean of given is the expectation of the beta posterior distribution, which for large is not far from the mode:
Let’s examine this result in an example. Suppose the prior distribution of is beta , and thus the prior mean is . Now suppose we are given that . Then the posterior distribution of given is beta with mean .
The graph below shows the two densities along with the corresponding means. The red dot is at the observed proportion of heads.
Run the cell again, keeping and but changing to 10 and to 7, then again changing to 1000 and to 700. The observed proportion is 0.7 in all cases. Notice how increasing the sample size concentrates the prior around 0.7. We will soon see the reason for this.
Also try other values of the parameters as well as and , including values where the observed proportion is quite different from the mean of the prior.
# Prior: beta (r, s)
# Given: S_n = k
# Change the values
r = 5
s = 3
n = 10
k = 7
# Leave this line alone
plot_prior_and_posterior(r, s, n, k)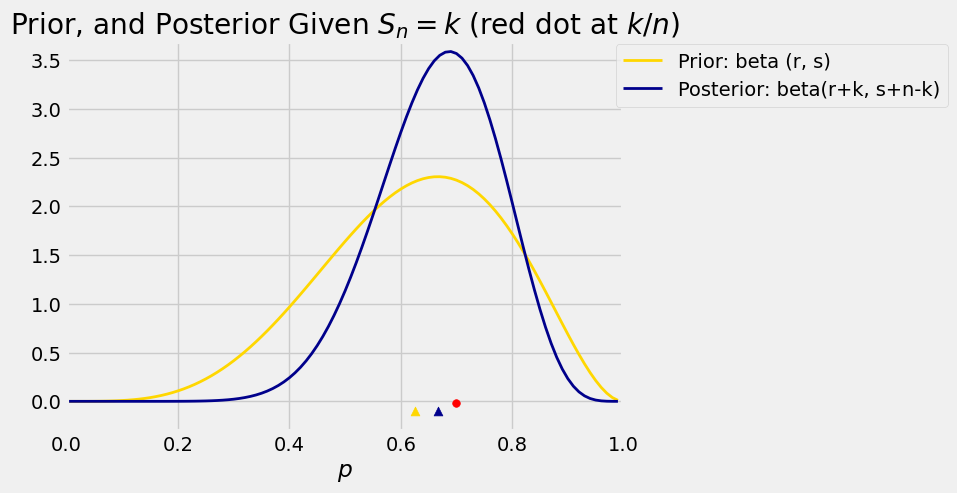
You can see how the data dominate the prior. The posterior distribution is concentrated around the posterior mean. The prior mean was 0.625, but given that we got 70 heads in 100 tosses, the posterior mean is 0.694 which is very close to the observerd proportion 0.7.
The formula for the posterior mean shows that for large it is likely to be close to the observed proportion of heads. Given , the posterior mean is
Therefore as a random variable, the posterior mean is
As the number of tosses gets large, the number of heads is likely to get large too. So the value of is likely to dominate the numerator, and will dominate the denominator, because and are constants. Thus for large , the posterior mean is likely to be close to .
21.1.7Prediction: The Distribution of Given ¶
As you saw in the previous chapter, the chance that a random coin lands heads is the expected value of its random probability of heads. Apply this to our current setting to see that
Now suppose that we have the results of the first tosses, and that of those tosses were heads. Given that , the possible values of are and . We can now use our updated distribution of and the same reasoning as above to see that
We can work out by the complement rule. We now have a transition function. Given that , the conditional distribution of is given by
In other words, given the results of the first tosses, the chance that Toss is a tail is proportional to plus the number of failures. The chance that Toss is a head is proportional to plus the number of successes.
You can think of the sequence as a Markov chain, but keep in mind that the transition probabilities are not time-homogenous – the formulas involve .