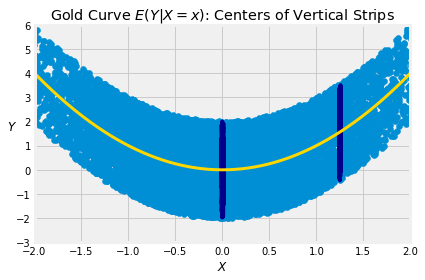
Suppose we are trying to predict the value of a random variable Y based on a related random variable X. As you saw in Data 8, a natural method of prediction is to use the “center of the vertical strip” at the given value of X.
Formally, given X=x, we are proposing to predict Y by E(Y∣X=x).
The conditional expectation E(Y∣X) is the function of X defined by
b(x)=E(Y∣X=x)
We are using the letter b to signifiy the “best guess” of Y given the value of X. Later in this chapter we will make precise the sense in which it is the best.
In random variable notation,
E(Y∣X)=b(X)
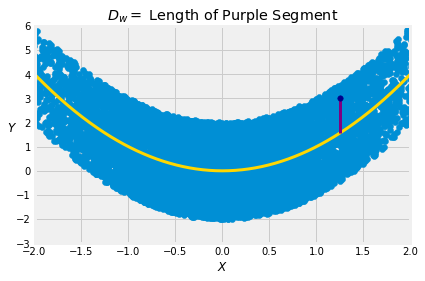
For a point (X,Y), the error in this guess is
Dw=Y−b(X)
The subscript w reminds us that this error is a deviation within a vertical strip – it is the difference between Y and the center of the strip at the given value of X.
The properties of conditional expectation are analogous to those of expectation, but the identities are of random variables, not real numbers. There are also some additional properties due to the aspect of conditioning. We provide a list of the properties here for ease of reference.
Linear transformation: E(aY+b∣X)=aE(Y∣X)+b
Additivity: E(Y+W∣X)=E(Y∣X)+E(W∣X)
“The given variable is a constant”: E(g(X)∣X)=g(X)
“Pulling out” constants: E(g(X)Y∣X)=g(X)E(Y∣X)
Independence: If X and Y are independent then E(Y∣X)=E(Y), a constant.
Let g(X) be any function of X. Then the covariance of g(X) and Dw is
Cov(g(X),Dw)=E(g(X)Dw)−E(g(X))E(Dw)=E(g(X)Dw)
By iteration,
E(g(X)Dw)=E(E(g(X)Dw∣X))=E(g(X)E(Dw∣X))=0
Thus the deviation from the conditional mean, which we have denoted Dw, is uncorrelated with functions of X.
This is a powerful orthogonality property that will be used repeatedly in this chapter. As an informal visual image, think of the space of all possible functions of X to be the surface of a table. Imagine Y to be a point above the table. To predict Y by a function of X it makes sense to find the point on the table that is closest to Y. So drop the perpendicular from Y to the table.
The point where the perpendicular hits the table is b(X). We say that the conditional expectation of Y given X is the projection of Y on the space of functions of X.
Dw is the perpendicular; it is orthogonal to the table.
In the next section we will see in exactly what sense b(X) is the best guess for Y.