It is reasonable to expect that if a random vector is multivariate normal then its components should have a joint density function. But we have to be careful about the components in order to discuss joint densities.
For an example of what could go wrong, let consist of i.i.d. standard normal variables, and let . Then the components of don’t have a joint density on the plane since all the probability is on the line . We have a degenerate situation in which one component is a linear transformation of the other.
Another example is . The three components don’t have a joint density in three dimensions, since the third component is a linear combination of the first two.
For a data scientist, there is no benefit in carrying around variables that are deterministic functions of other variables in a dataset. So we will avoid degenerate cases such as those above. To do this, let’s make an observation about the linear transformations involved.
In both cases, if you write as then the matrix is not invertible, and the covariance matrix of is positive semi-definite instead of positive definite.
Thus we are going to restrict the definition of multivariate normal vectors to invertible linear transformations of i.i.d. standard normal vectors and positive definite covariance matrices.
🎥 Multivariate Normal
23.3.1The Density¶
From now on, we will usually say “density” even when we mean “joint density”. The dimension of the random vector will tell you how many coordinates the density function has.
Let be a positive definite matrix. An -dimensional random vector has the multivariate normal density with mean vector and covariance matrix if the joint density of the elements of is given by
We will say that the elements of are jointly normal or jointly Gaussian.
You should check that the formula is correct when . In this case is just a scalar. It is a number, not a larger matrix; its determinant is itself; its inverse is simply . Also, and are just numbers. The formula above reduces to the familiar normal density function with mean and variance .
You should also check that the formula is correct in the case when the elements of are i.i.d. standard normal. In that case and , the -dimensional identity matrix.
When the multivariate normal distribution is called bivariate normal.
🎥 Multivariate Normal Parameters
In lab you went through a detailed development of the multivariate normal joint density function, starting with consisting of two i.i.d. standard normal components and then taking linear combinations. It turns out that all non-degenerate multivariate normal random vectors can be generated in this way. In fact, there are three useful equivalent definitions of a random vector with the multivariate normal density.
🎥 Multivariate Normal Definition
Definition 1: for some i.i.d. standard normal , an invertible , and a column vector .
Definition 2: has the joint density above.
Definition 3: Every linear combination of elements of is normally distributed.
At the end of this section there is a note on establishing the equivalences. Parts of it are hard. Just accept that they are true, and let’s examine the properties of the distribution.
The key to understanding the multivariate normal is Definition 1: every multivariate normal vector that has a density is an invertible linear transformation of i.i.d. standard normals. Let’s see what Definition 1 implies for the density.
🎥 Multivariate Normal Density
🎥 Quadratic Form
23.3.2Quadratic Form¶
The shape of the density is determined by the quadratic form . The level surfaces are ellipsoids. In two dimensions these are the ellipses you saw in lab.
Here is the joint density surface of standard normal variables and that are jointly normal with . The call is Plot_bivariate_normal(mu, cov) where the mean vector mu is a list and the covariance matrix is a list of lists specifying the rows.
mu = [0, 0]
cov = [[1, 0.8], [0.8, 1]]
Plot_bivariate_normal(mu, cov)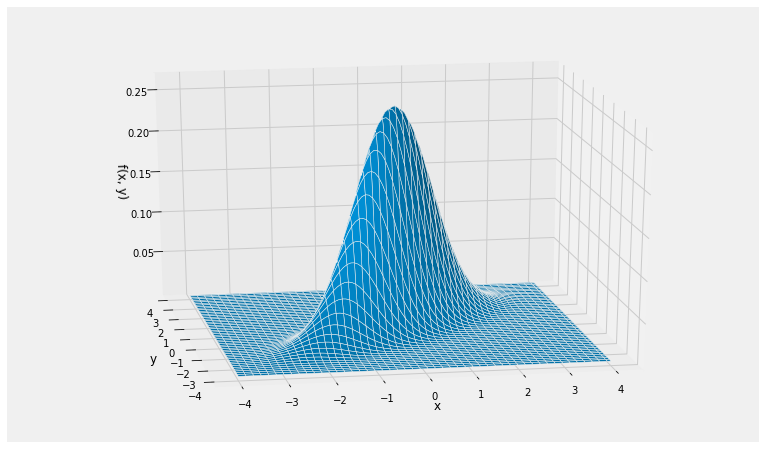
Note the elliptical contours, and that the probability is concentrated around a straight line.
In more than two dimensions we can no longer draw joint density surfaces. But in three dimensions we can make i.i.d. draws from a multivariate normal joint density and plot the resulting points. Here is an example of the empirical distribution of 1000 observations of standard normal variables , , and that are jointly normal with , , and . Note the elliptical cloud.
The call is Scatter_multivariate_normal(mu, cov, n) where n is the number of points to generate. The function checks whether the specified matrix is positive semidefinite.
mu2 = [0, 0, 0]
cov2 = [[1, 0.6, 0.5], [0.6, 1, 0.2], [0.5, 0.2, 1]]
Scatter_multivariate_normal(mu2, cov2, 1000)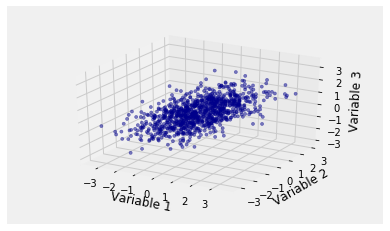
To see how the quadratic form arises, let be multivariate normal. By Definition 1, for some invertible and vector , and some i.i.d. standard normal .
By multiplication of the marginals, the joint density of is
The preimage of under the linear transformation is
and so by change of variable the quadratic form in the density of is
Let be the mean vector of . Because , we have .
The covariance matrix of is . So the covariance matrix of is
So the quadratic form in the density of becomes .
🎥 Volume
23.3.3Constant of Integration¶
By linear change of variable, the density of is given by
where is the preimage of and is the volume of the parallelopiped formed by the transformed unit vectors. That is, . Now
Therefore the constant of integration in the density of is
We have shown how the joint density function arises and what its pieces represent. In the process, we have proved the Definition 1 implies Definition 2. Now let’s establish that all three definitions are equivalent.
23.3.4The Equivalences¶
Here are some pointers for how to see the equivalences of the three definitions. One of the pieces is not easy to establish.
Definition 1 is at the core of the properties of the multivariate normal. We will try to see why it is equivalent to the other two definitions.
We have seen that Definition 1 implies Definition 2.
To see that Definition 2 implies Definition 1, it helps to remember that a positive definite matrix can be decomposed as for some lower triangular that has only positive elements on its diagonal and hence is invertible. This is called the Cholesky decomposition. Set to see that Definition 1 implies Definition 2.
So Definitions 1 and 2 are equivalent.
You already know that linear combinations of independent normal variables are normal. If is an invertible linear transformation of i.i.d. standard normal variables , then any linear combination of elements of is also a linear combination of elements of and hence is normal. This means that Definition 1 implies Definition 3.
Showing that Definition 3 implies Definition 1 requires some math. Multivariate moment generating functions are one way to see why the result is true, if we accept that moment genrating functions determine distributions, but we won’t go into that here.