# HIDDEN
import warnings
warnings.filterwarnings('ignore')
from datascience import *
from prob140 import *
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
%matplotlib inline
import math
from scipy import stats
Linear transformations are both simple and ubiquitous: every time you change units of measurement, for example to standard units, you are performing a linear transformation.
Let T have the exponential (λ) distribution and let T1=λT. Then T1 is a linear transformation of T. Therefore
E(T1)=λE(T)=1andSD(T1)=λSD(T)=1
The parameter λ has disappeared in these results. Let’s see how that follows from the distribution of T1. The cdf of T1 is
FT1(t)=P(T1≤t)=P(T≤t/λ)=1−e−λ(t/λ)=1−e−t
That’s the cdf of the exponential (1) distribution, consistent with the expectation and SD we found above.
To summarize, if T has the exponential (λ) distribution then the distribution of T1=λT is exponential (1).
You can think of the exponential (1) distribution as the fundamental member of the family of exponential distributions. All others in the family can be found by changing the scale of measurement, that is, by multiplying by a constant.
If T1 has the exponential (1) distribution, then T=λ1T1 has the exponential (λ) distribution. The factor 1/λ is called the scale parameter.
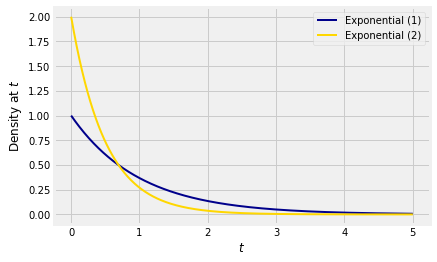
Here are graphs of the densities of T1 and T=21T1. By the paragraph above, T has the exponential (2) distribution.
Let’s try to understand the relation between these two densities in a way that will help us generalize what we are seeing in this example.
The relation between the two random variables is T=21T1.
For any t, the chance that T is near t is the same as the chance that T1 is near s=2t. This explains the factor e−2t in the density of T.
If we think of T1 as a point on the horizontal axis, then to create T you have to divide T1 by 2. So the transformation consists of halving all distances on the horizontal axis. The total area under the density of T must equal 1, so we have to compensate by doubling all distances on the vertical axis. This explains the factor 2 in the density of T.
Answer
cλ
🎥 Linear Change of Variable
16.1.2Linear Change of Variable Formula for Densities¶
We use the same idea to find the density of a linear transformation of a random variable.
Let X be a random variable with density fX, and let Y=aX+b for constants a=0 and b. Let fY be the density of Y. Then
fY(y)=fX(ay−b)∣a∣1
Let’s take this formula in two pieces, as in the exponential example.
For Y to be y, X has to be (y−b)/a.
The linear function y=ax+b involves multiplying distances along the horizontal axis by ∣a∣; the sign of a doesn’t affect distances. To get a density, we have to compensate by dividing all vertical distances by ∣a∣.
This is a good way to understand the formula, and will help you understand the corresponding formula for non-linear transformations.
For a formal proof, start with the case a>0.
FY(y)=P(aX+b≤y)=P(X≤ay−b)=FX(ay−b)
By the chain rule of differentiation,
fY(y)=fX(ay−b)⋅a1
If a<0 then division by a causes the direction of the inequality to switch:
Let the distribution of U be uniform on (0,1) and for constants b>a let V=(b−a)U+a. In an earlier section we saw that V has the uniform distribution on (a,b). But let’s see what’s involved in confirming that result using our new formula.
First it is a good idea to be clear about the possible values of V. Since the possible values of U are in (0,1), the possible values of V are in (a,b).